Behavioral data for frontier AI.
Trusted by the leaders in AI
Why AI labs and Enterprises choose Prolific
A unified infrastructure to design, launch, and manage human data workflows at frontier speeds.
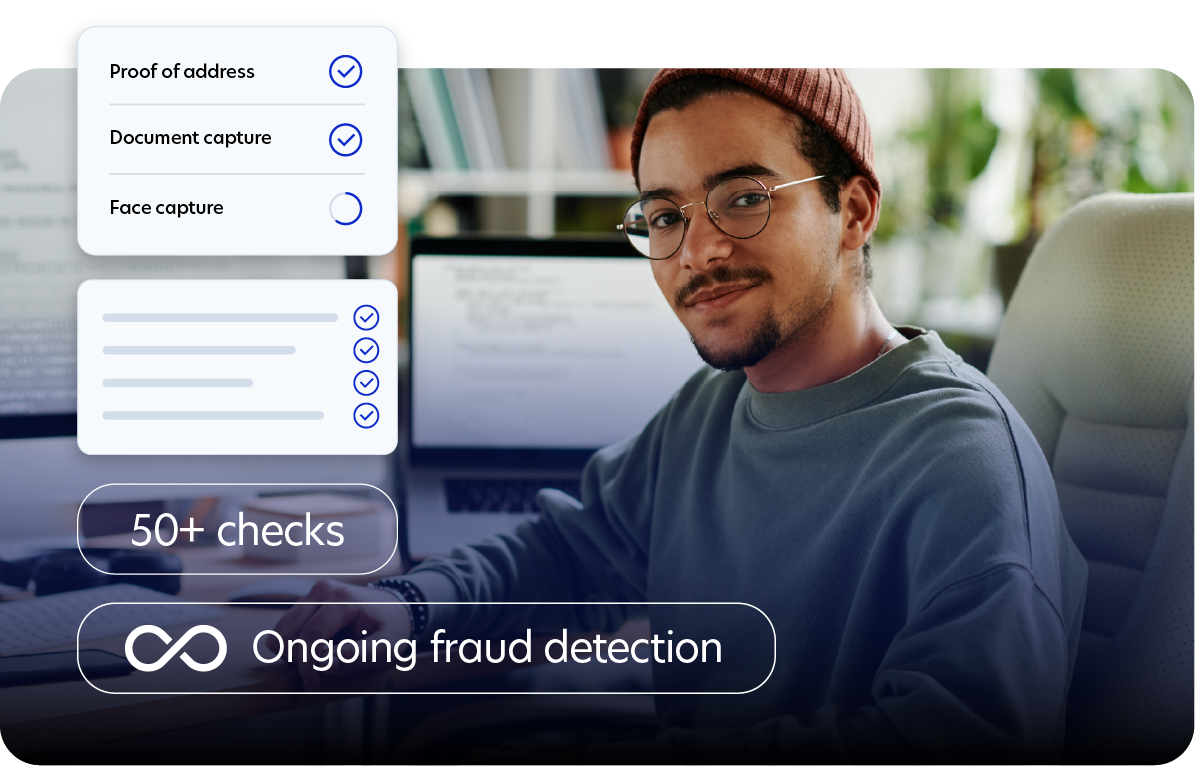
Specialist human intelligence, profiled for advancing models
Behind every evaluation is a carefully profiled, verified human. We combine demographic, behavioral, and domain-level profiling with ongoing verification to surface people who deliver reliable human data, when you need it.
Automate human data collection
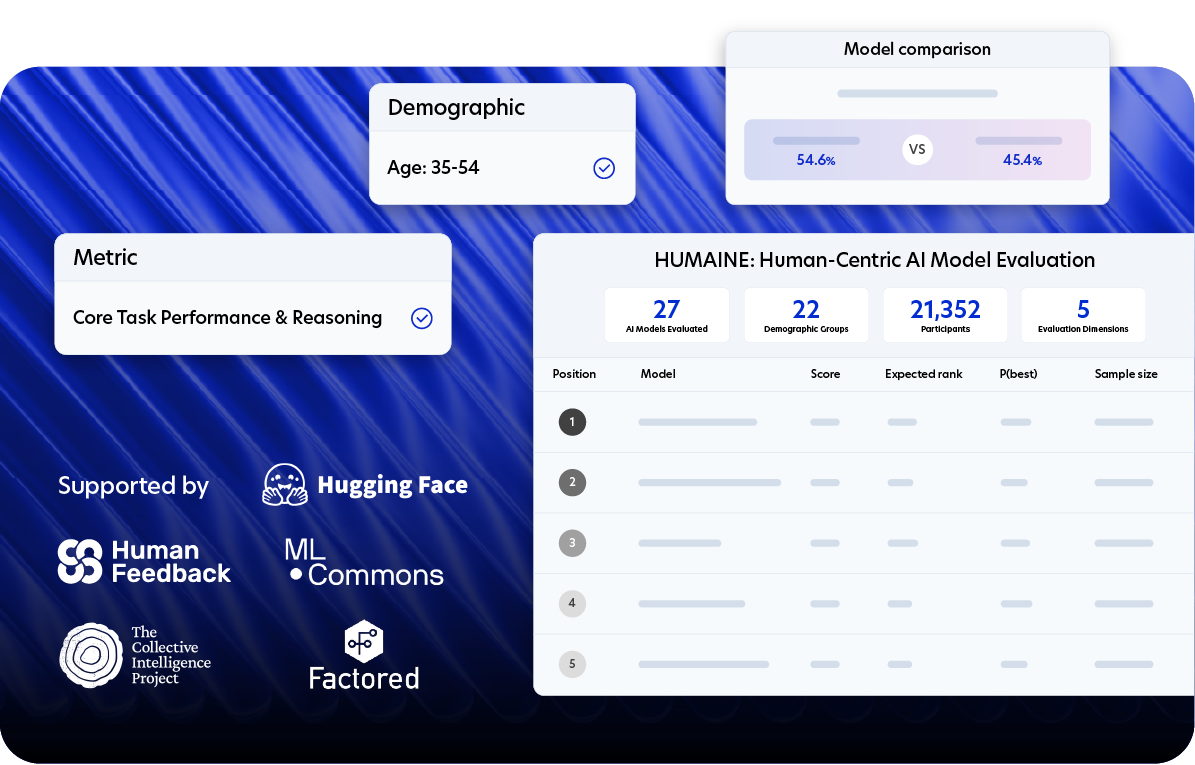
We build custom evaluations from the ground up
HUMAINE is a public benchmark and evaluation framework for assessing model behavior in real-world, human-facing conditions. Developed through peer-reviewed research and ongoing empirical work, it allows model builders to run human-centered evaluations - supporting systematic comparison, diagnostics, and iteration on deployed models.
Read how Prolific collaborates with industry innovators
Peer-reviewed research using data from Prolific.

Access AI research opportunities
Questions?
Teams building leading frontier AI models and AI products use Prolific for model evaluation, RLHF data collection, safety testing, and UX research. Our platform works with any annotation tool that generates URLs, supporting all data modalities - text, image, audio, and video.
We give you direct access to 200,000+ verified participants through an API-first platform - no hired annotation teams or black-box operations. Host tasks on your infrastructure, access people and experts from all walks of life, and get results in hours instead of weeks.
You will start to see data typically arrive within hours. Simple tasks can complete on the same day, while specialized domain expert tasks may take a few days depending on requirements.
We manage quality by maintaining a bar for entry and participation on our platform. We have 200,000+ active participants on the platform, with over a million on the waitlist. Protocol, our AI-powered quality monitoring system, runs 40+ checks to verify identity during onboarding and analyze behavioral data when they contribute data to ensure only verified participants are on the platform. You have full control over submission approval and can reject submissions that show negligent behavior (e.g. failed attention and comprehension checks). For more details on approvals and rejections, check out our help center article.
Our 300+ prescreeners lets you access 200,000+ participants from our Global Crowd. These prescreeners cover a range of profile information including demographics, their personal and professional background, and their Prolific submissions history among other things. Additionally, you can also access AI Taskers and Domain Experts - participants verified for their skills in AI training and evaluation tasks and subjects like STEM, programming, healthcare and others.
Yes. Many teams using Prolific use their custom annotation tools or third-party solutions that generate a task URL - which you can connect participants with using our UI or API. Alternatively, you can also use AI Task Builder for text annotations and evaluations.
Our pricing is straightforward and transparent:
- When you’re accessing the platform directly, you pay a participant reward that you set, plus a platform fee.
- When you need managed services, pricing is calculated based on your project scope and requirements.
For more details, visit our pricing page.
Typically, we recommend you pay participants at least £9.00 / $12.00 per hour, while the minimum pay allowed is £6.00 / $8.00 per hour. For tasks requiring specialized skills (like experience in AI annotation tasks, coding experience, or advanced STEM degrees), we recommend higher compensation to reflect their expertise and the complexity of the tasks. Fair compensation leads to better data quality and higher engagement, especially when publishing complex tasks or studies. For more details, visit our pricing page.




